
We are a group of creative people who help organizations make their ideas beautiful.
Using AI to Capture the Essence of Agency Language
Once again our feeds have been inundated with articles about the potential for, and implications of, AI-generated content. But what’s it all mean, really?
Though it’s been exhilarating to engage in the speculation and experimentation that has surrounded each recent development in image and language generation, most articles seem to focus far more attention on prophecy than practice; they rarely provide demonstrations beyond playing with the publicly accessible defaults. As fun as it is to endlessly replicate and extend this manner of play, readers are ultimately left with little other than a sense of astonishment and a confidence that someone else is going to do something very cool with these technologies. In this article, we’ll outline a path to overcome this sense of alienating urgency and explore how you can most effectively use available technologies, tailoring them to perform specific tasks suited to your work.
Cost and Complexity of AI-Driven Work
At Paradowski Creative, my role as AI Lead involves guiding the strategic direction of our AI initiatives and collaborating with teams to recognize and prioritize Machine Learning opportunities. Many ML projects never make it to production, and countless more are never attempted out of fear that the implementation would be too costly or complex. Without a team of researchers and an enormous cloud budget, how can you expect to achieve the performance of headlining models? Moreover, it can be immensely frustrating to interact with incredible tools like ChatGPT and StableDiffusion and feel unable to differentiate yourself from other organizations who possess the same access to the same resources.
The path to achieve higher performance, lower costs, and differentiable capabilities on top of state-of-the-art models is immediately accessible through an approach known as transfer learning. Over the course of this article we’ll explore an exercise our agency recently performed: fine-tuning OpenAI’s GPT-3 with curated web data to generate industry-specific language. We’ll be poking a bit of fun at our own industry’s attraction to certain patterns of speech, addressing limitations of fine-tuning, and providing a backdrop to discuss more practical applications and inherent risks of employing generative AI in our creative process. But first, let’s briefly review the principal technologies and terms we’ll be using in our exercise.
Building on Language Models
We’ll be focusing on variations of OpenAI’s GPT (General Pre-trained Transformer) language models to benefit from their low barrier to entry and industry-leading performance; the broader discussion and strategy of adapting a model for specialized purposes will be applicable to any pre-trained machine learning model. The latest explosion in discussions of generative AI were ignited by OpenAI’s research preview ChatGPT, echoing astonishment brought by their initial release of GPT-3 in the (now incredibly distant-seeming) summer of 2020. ChatGPT is capable of producing astoundingly convincing expert-like dialogues on an unprecedented number of topics, but is fundamentally an iteration on OpenAI’s continual release of models calibrated to overcome limitations of their earlier LLMs (Large Language Models). Following prior successes of Codex and InstructGPT (respectively optimized for natural language translation to code and instruction following) OpenAI has, with ChatGPT, further demonstrated the wide range of applications and broad potential of models derived from their core architecture.
If you haven’t interacted with any of OpenAI’s language models before, the experience is quite intuitive. Through the web interface or API, users provide a selected model with a “prompt” (e.g., “Compose a more eloquent way to say ‘someone doing something very cool’”; “Provide a concise one-sentence summary of the previous paragraph in simple english”) and receive a “completion” (e.g., “individual executing a remarkable feat of prowess.”) Charges are based on the model selected and accrued on a per-token basis, which includes both the prompt and completion. Tokens are essentially pieces of words, or common sequences of characters, which the model operates on when processing text.
When working with GPT-3 on simple tasks like summarization, a "zero-shot" approach is often used where a single, simple instruction is provided as the prompt (see above). For more complex requests, a "multi-shot" prompt may be used, which includes multiple examples of ideal prompt-completion pairs. During inference, the model takes the input prompt and predicts the token that is statistically most likely to occur next in text. There’s much more going on behind the scenes here which we won’t be covering, but for the curious, Jay Alammar provides a visual representation of the process.
GPT-3 is very capable at general tasks, but performs best on specific tasks when given a maximum number of guiding examples. Without fine-tuning, there are severe limitations for the number of examples and amount of influence one can exert on the completions generated. A core goal of GPT-3's development was to construct a model flexible enough to bypass the need to prepare specific language models for individual language problems. This generalizability makes GPT-3 very adept at performing zero or few shot performance, though will perform much better on tasks when given as many representative examples in a prompt as possible to guide output generation.

MidJourney Prompt: file folders in a cardboard box in modern office space people using fire for warmth, employees throwing File folders, Papers flying through air, burning file folders --ar 3:2 --v 4
The key to going beyond basic use of these models lies in an approach to transfer learning known as fine-tuning. This technique significantly lowers the barrier to entry for machine learning, allowing a model trained on one task to be repurposed for another related task. Given some existing model as a starting point, a new model can be trained with a much smaller dataset while retaining feature extraction from the original model. For instance, an image classification model trained on millions of images and thousands of object classes could be used as the starting point for a model trained on a much smaller set of images for a task-specific classification, like identifying flower varieties. Transfer learning effectively allows the new model to benefit from the knowledge learned by the pretrained model without requiring large amounts of data and expensive compute resources.

MidJourney Prompt: Transferring data from one brain to another brain in modern office --ar 2:1 --test --creative
Attempting to utilize the default GPT-3 model in an actual project reveals several limitations. High generalizability inevitably leads to completions wandering outside the intended domain – even when providing multiple examples in the prompt. Furthermore, provision of examples in the prompt is severely limited; GPT-3 requests can use a maximum of 4097 tokens shared between prompt and completion (with charges accrued per token used). Attempting to improve the quality of responses quickly presents contradictory incentives when engineering prompts with the base model.
The ability to fine-tune GPT-3 resolves the complexity of managing our token allowance; with a fine-tuned model we no longer need to provide examples or comprehensive instructions in our prompts. In addition to significantly lowering our accrued token usage costs, this approach allows us to exert greater control over received completions, achieve higher quality outputs, and reduce request latency.
The Exercise:
Fine-Tuning OpenAI's GPT-3 with Curated Data
The original inspiration for our exercise developed from conversations about the grandiose language often found in the self-promotional materials of ad agencies. We aimed to tune a model capable of generating outputs that could readily be fed into a template in order to generate imagined agency websites on each visit. This potential application very much would follow in the footsteps of the multitude of “this [entity] does not exist” websites that accompanied early advancements in generative AI.

MidJourney Prompt: Portraits of faceless co-workers in modern office, working on computers in meeting --ar 2:1 --v 4
The first, and largest, piece of training or fine-tuning a machine learning model is sourcing and preparing an adequate amount of sample data. To support our goal, we needed to construct a series of representative prompts and completions. We sourced agencies operating in our industry from a list of Webby Award entries and constructed a simple web-crawler that scraped a well-known professional networking site for details to interpolate into consistent prompts:
“# [Paradowski Creative](http:\/\/www.paradowski.com)\n ## A company specializing in: Advertising, Strategy, Brand Identity, Creative Technology, Experience Design, Content Creation, Video Production, and Media Planning.\n->”
A second web-crawler was written to scrape each organization’s website for contentful text, which served as our sample completions:
“### We are a group of creative people ### who help organizations ### make their ideas beautiful. > If you dropped by the agency right now, you'd find roughly 125 writers, designers, strategists, producers and developers working on all kinds of amazing stuff. […]”
We constructed around 500 examples, structuring and preparing our data using the OpenAI Python Library.
After gathering data, the next step was to generate a series of initial fine-tunes, evaluating and adjusting our data until we receive reasonable outputs. With ~500 examples and training using the “curie” base model, our fine tunes took around ten minutes to train, however this will vary depending on the model selected, number of examples, and availability of the service.

MidJourney Prompt: Clock that powered by a treadmill in a modern office. Human walking on treadmill --ar 2:1 --v 4
It’s best to begin with the simplest model that performs reasonably well, then work your way up as you adjust the content and format of your examples until you cease to see improvements. This initial discovery process is immensely important; in our case it guided us toward converting our input and completions into the markdown format portrayed above. We also found it necessary to manually step through our completions to remove references to UI elements, legal text, and contextless proper nouns that were distracting from the self-descriptive text we wanted the model to focus on.
At this point our model should be outputting results that are roughly equivalent to a multi-shot inference performed by the based model. This is a good point to begin looking at more advanced metrics and make more objective adjustments to our fine-tune. At the completion of each fine-tune job, a results file is attached to your job providing metrics for each step of the training process. Since we’re performing a conditional generation, where completions are contingent on the prompts, we focused on loss and accuracy metrics. There are two available types of accuracy metrics, which measure both the percentage of individual tokens and the full sequence of tokens correctly predicted at each step over a batch of our training data.
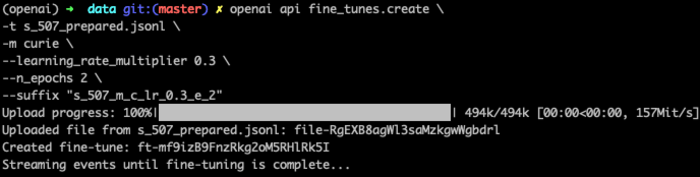
Creating a fine tune with the OpenAI CLI
Manually accessing and evaluating these metrics between each exercise would be extremely tedious. Fortunately, OpenAI provides an effortless integration with the Weights and Biases MLOps platform to track and graphically compare your experiments. Weights and Biases further provides an excellent interactive Google Colab notebook and overview of performing GPT-3 exploration with their tooling.
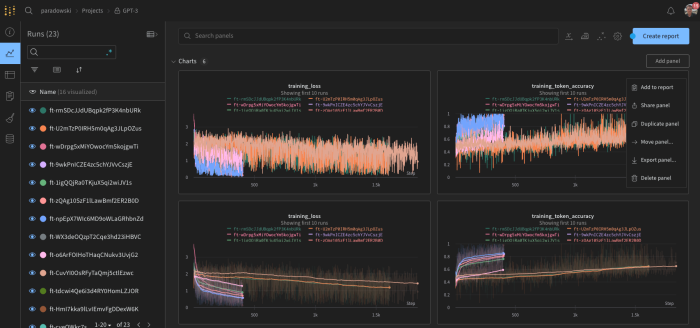
The Weights and Biases dashboard
The progression from this point forward will be to adjust hyperparameters (starting with simple properties like learning rate and number of epochs), run a fine-tune job, then sync your results to Weights and Biases to compare results to previous experiments. If relevant metrics have improved, try adjusting them further in that direction until improvements cease or other negative effects occur.
Speaking of other negative effects, we’ll need to be especially wary of producing a model that performs very well within our training data, but generalizes poorly to new prompts. This is referred to as overfitting – typically caused by training a model with too little data, too high of a learning rate, or for too many epochs. This is of particular concern in projects like ours; we want to capture tendencies of the language in our training data without exactly replicating the completions.
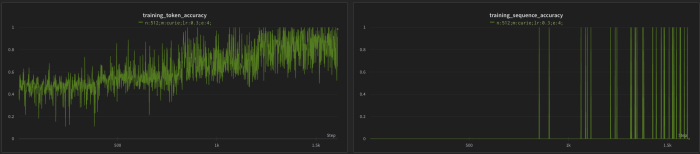
Sudden jumps to perfect token or sequence accuracy are a definite sign of overfitting.
After around thirty experiments, working up from simpler to more complex models, we settled on a set of hyperparameters that allowed us to train for four epochs while avoiding noticeable overfitting. Even working close to the minimum number of training samples OpenAI’s documentation recommends for this type of exercise, our fine-tuned model consistently produces valid hierarchical markdown and cohesive industry-aligned language.
Example output
# We Are a Creative Agency.
## Driven by curiosity and creativity, we take brands from concept to consumers.
### Always open to new ideas
> ________ is a full-service creative agency that drives results through strategic thinking, brand creation, visual design and digital innovation. Our clients are leaders in their industries who appreciate our seasoned approach to solving problems with a focus on what's best for the customer.
## Let's Talk About Your Project...
> We can work with you directly or assign an account executive specifically for your project if needed.
Focused on a single organization’s web content, it’s easy to see how this approach could be adapted to propose product descriptions, copy, and social posts that are consistent with a brand’s tone and style.
These outputs are impressive, but carry severe risks and limitations. Regardless of the quality or quantity of data we bring to our fine-tune, all machine learning models encode the biases and stereotypes of their original training data. OpenAI provides impressive content moderation tooling and built-in protections to reduce risks, but it’s not advisable to allow end-users to engage in open-ended interactions with a language model (OpenAI might not approve such an application to go live in the first place).
In our case, we employed the outputs of our fine-tuned model in a novel way, curating some of the more eccentric completions to populate a series of whimsical AI assisted layouts that temporarily took over the home page of our company website. My colleague, Jon Simons, crafted some magnificent designs with AI-generated imagery to bring this concept to fruition.
Using Generative AI in an assistive capacity, we are able to gain inspiration and new interpretations from limited data that would otherwise be inaccessible to us. The fundamental concepts that present immediately apparent creative applications also underlie the capability of these tools to deliver valuable data-handling services to businesses. Stylized generation is an accessible and entertaining exercise to get a taste of this approach, but the real strength of fine-tuning GPT-3 lies in direct classification, text encoding, and entity extraction.
Fine-tuned language models are able to reduce latency in customer communications and personalize content for custom campaigns: in addition to now-familiar tasks like language translation and summarization, these models can be used to analyze customer feedback and reviews, extract and classify information from email communications, and answer specific questions within nodes of dialog trees. The field of digital marketing, along with other domains, harbors an enormous potential for adding efficiencies and insights to your regular (or irregular, as often occurs) data-processing initiatives. Through transfer-learning, you can move beyond merely playing with cutting-edge technologies off the shelf, and apply them directly within your field.

MidJourney Prompt: office worker closeup of fine tuning gear with tool in modern office. gear connected to modern computer, tightening gear --ar 2:1 --v 4
While we’re not able to fine-tune InstructGPT, Codex, or ChatGPT, or modify these models with more advanced techniques like Human Reinforced Learning, we can still far outperform base pretrained models on a variety of tasks – at a much lower initial cost and barrier to entry than it would appear from the outside looking in. As new models are released (GPT-4, future iterations of the open source BLOOM LLM, image generation models) more opportunities will emerge to transfer their capabilities to specific problems. By learning to refine and apply these tools to specific applications, organizations and individuals can make extraordinary use of these technologies, and emerge from their efforts as someone doing something very cool.